We're going to turn our Django model into a web service using the python package "tastypie"
What is tastypie? Honestly, I don't really know. But, I do know how to make it return .json and xml API-like resources for a properly set up database schema!
Let's install tastypie. From inside our django project directory use pip:
(django-jay) PS C:\Python27\home\jtarlecki\djcode\django-jay\rebates> pip install django-tastypie
Let's also pip some additional xml support.
(django-jay) PS C:\Python27\home\jtarlecki\djcode\django-jay\rebates> pip install defusedxml "lxml>=3"
Now, let's create a new file inside our app (rebate) called
api.py
(django-jay) PS C:\Python27\home\jtarlecki\djcode\django-jay\rebates> start notepad++ rebate\api.py
Inside
api.py, append the following code
from tastypie.resources import ModelResource
from tastypie.constants import ALL
# constant ALL sets the types of query types we can perform on our models.
from models import Zipcodes
class ZipcodesResource(ModelResource):
class Meta:
queryset = Zipcodes.objects.all() #this is everything in the zipcodes table
resource_name = 'zipcodes'
# basically, this give the url path
# localhost:8000/<project-level-url>/<app-level-url>/resource_name/
When we first ran django-admin.py startapp rebate , django created a collection of files inside our rebate app:
+---rebate
¦ admin.py
¦ models.py
¦ tests.py
¦ views.py
¦ __init__.py
So, we just added
api.py, now we need to add
urls.py to our app to help give this thing some specificity within the app. It doesn't really matter where we put it (we could put this at the project level) but for now, let's leave it here:
(django-jay) PS C:\Python27\home\jtarlecki\djcode\django-jay\rebates> start notepad++ rebate\urls.py
Inside this app-level urls.py file, append the following code:
from django.conf.urls import patterns, include, url
from rebate.api import ZipcodesResource
#now that ArticleResource is imported, create an instance of it
zipcode_resource = ZipcodesResource()
urlpatterns = patterns('',
url(r'^api/',include(zipcode_resource.urls)),
# these urls are automagically created by our ModelResource class from api.py
)
To explain some of the comments above: we're going to pull in the ZipcodesResource() class from
api.py then create an instance of it at runtime. Then using some tastypie wizardry, the ModelResource class imported in
api.py automagically creates some urls for us to use. Le'ts promise ourselves to r
ead more about it here later.
At this point we are officially daisy-chaining some urls. Make sure your entire django project has some clue about its enclosed apps. Fire up the
urls.py from the project directory (rebates):
(django-jay) PS C:\Python27\home\jtarlecki\djcode\django-jay\rebates> start notepad++ rebates\urls.py
Inside
rebates\urls.py, append the following url pattern:
url(r'', include('rebate.urls')),
Basically, this is just a pass-through that allows the /api/ url we defined at the
app-level to be the top-level url at the
project-level. Confused? Yes, it is confusing. If you mess around with it, you will get it.
OK great! Now lets run the server
(django-jay) PS C:\Python27\home\jtarlecki\djcode\django-jay\rebates> python manage.py runserver
And navigate our web browser to the following :
http://localhost:8000/<project-level-url>/<app-level-url>/resource_name/
or
http://localhost:8000/api/zipcodes/
as our <project-level-url> is simply a pass-through as described above.
Oops! Tastypie isn't the cleanest with urls. You should see the following message prompting you to put a little additional info into your url
Sorry, not implemented yet. Please append "?format=json" to your URL.
OK. Let's append that to the end of our url.
http://localhost:8000/api/zipcodes/?format=json
Awesome! We get a response, along with some metadata to help give context for what the response actually is.
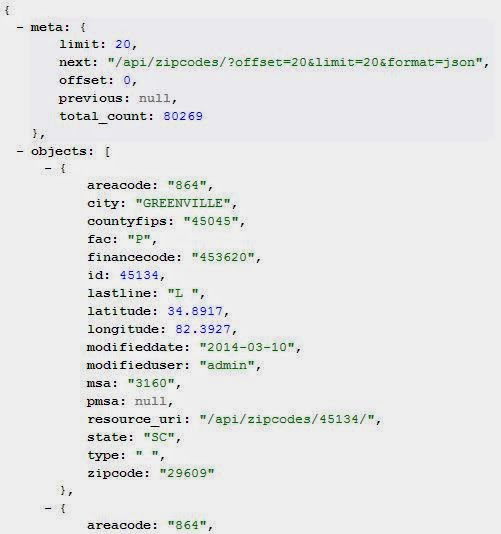 |
| Its a big table, so tastypie by default gives responses in chunks of twenty (20) records. Screen snippet above. |
By default, tastypie also allows you to put a primary key number as the next-level-down url. Say we wanted to see the detail on the first object pictured above (id=45143), we could call it with the following url:
http://localhost:8000/api/zipcodes/45134/?format=json
Which give the following resultant:
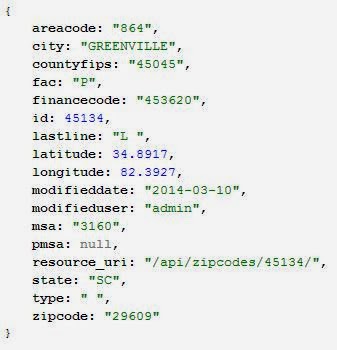 |
| response |
Some of you probably noticed the
recouse_uri field annotated in the previous picture. All I did was copy that in to my browser. Notice that tastypie has a built in url pattern for primary keys of tables you hook into its built-in resources, which has the form:
http://localhost:8000/api/zipcodes/<pk>/?format=json
where <pk> is the primary key number from your table.
I'm still getting xml errors because of something missing in my installed lxml.
I tried re-installing from pip, but still get the error. For now, I'm only concerned with .json responses anyway, so I'm just going to skip for now.
If we want to add a filter to our urls (say, we want a response based on a specific query), we can add a filter to the
api.py file. Let's say we want to search for zipcode information by zipcode, since someone who is using this api probably has no idea what our primary keys are in our database.
Thus, let's put a zipcode filter in our
api.py file.. append the following inside the
meta class of the
ZipcodesResource class:
filtering = {
"zipcode": ('exact'),
}
There are many different filters you can add, but right now we will look at the exact match.
Access the following url
http://localhost:8000/api/zipcodes/?zipcode=19104&format=json
Voila! Now we have a list of zipcode info for 19104! Read up on the tastypie docs for more info.